What’s Missing for Robot Foundation Models?
Progress and Missing Pieces on the Frontier of Robotics + AI

These are annotated and expanded slides from invited talks I gave this year. Recorded version of this talk from CVPR, here.

A massive vibe shift has rocked the world this year, and its name is intelligent robots. From academic research to an exploding startup scene to industry AGI labs, the dream of general purpose agents embodied in the physical world has captured the world’s attention. But is the arrival of ubiquitous general-purpose robots – powered by robot foundation models – truly just around the corner?
Beneath all of the polished and hyped-up demo videos, I think it’s important to examine how the field of robotics and AI is actually evolving. When we peel back the marketing narratives which are optimized for storytelling and fundraising, can we see how the underlying scientific and technological progress is going? Can we examine what’s going well, and perhaps more importantly, what’s still missing? What are the open challenges and blind spots of robot foundation models, and what can that tell us about what’s coming next?

In today’s talk, I’ll attempt to provide some data points which shine light on some missing pieces for robot foundation models and initial progress towards addressing these. But first, let’s get on the same page: why should we care about robot foundation models in the first place?

We can start with a simple overview of how classical robotics has approached the control problem. In the “Sense-Plan-Act” setting, we have a pipelined system with modules responsible for Perception, Planning, and Actuation.
But what we’ve seen in the past few years is that off-the-shelf Vision Language Models (VLMs) and Large Language Models (LLMs) have made for extremely strong perception and reasoning systems. By training on an entire internet’s worth of visual-language data, these foundation models have distilled a ton of visual and semantic world understanding – properties which are very useful in robotic sensing and planning, especially in unstructured and open-world situations! And for low-level actuation, we have seen tremendous progress in end-to-end learning with data-driven methods like imitation learning and reinforcement learning.
However, there are two main issues with the modular “Foundation Models as Experts” setting. The first is that the off-the-shelf foundation models we use were not built with real-world interaction in mind! The VLMs and LLMs we often use are those designed for academic vision benchmarks, for multi-turn dialogue, for captioning internet images – but definitely not optimized for robotics scenarios. The fact that they are often useful for robotics is a nice gift, but it’s clear that this can’t always be expected or relied upon; for example, BERT collapses many important robotics concepts (“left” and “right”) into the same part of it’s latent space, and CLIP is infamous for struggling with precise and spatial visual understanding, requiring substantial finetuning on robotics domains to be useful. This is neither a feature nor a bug; robotics was simply just not a priority at all when designing and training these models. We can do better!

The second issue is that the way we currently glue together these modules is extremely constrained! Since off-the-shelf foundation models share text input/output as a common modality, we’ve leveraged language as the connective tissue between different expert models. We’ve set up fairly arbitrary borders between these expert modules, and bottlenecked their communication channels to usually very simple and limited text.
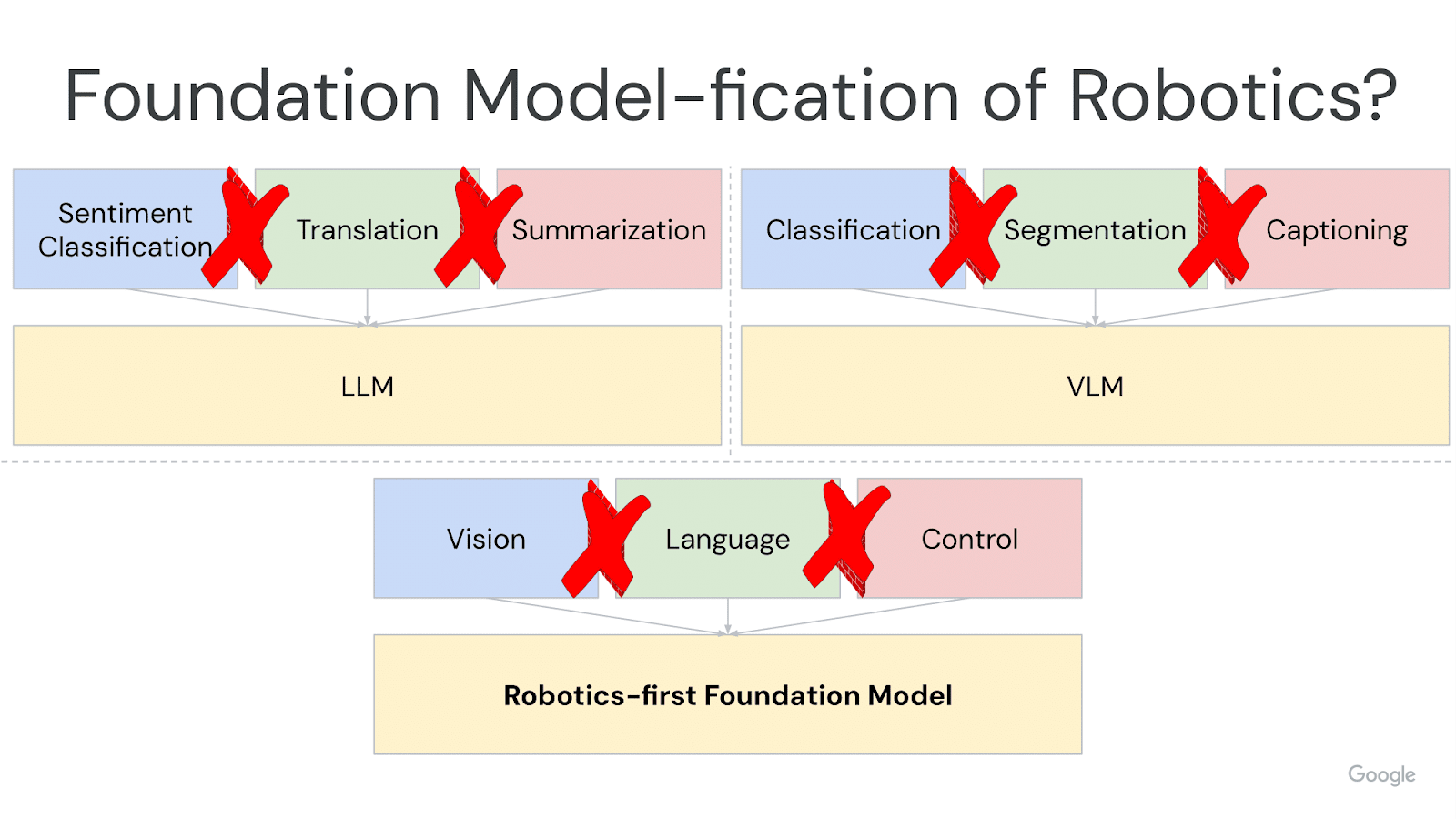
Over time, we can expect that these arbitrary walls between Perception, Planning, and Action will start to go away. Just as we have seen in NLP and Vision, the natural drive as a field matures is to blur the artificial lines which separate capabilities and tasks. Hopefully, with robot foundation models, we’ll see the same trends that we saw in NLP and CV: that combining seemingly separate tasks together with shared training objectives (ie. seq2seq next token prediction) leads to positive transfer, the ability to learn each individual task better when these different tasks are learned together.

That by itself is a pragmatic reason to explore the promise of robot foundation models! Perhaps we’ve pushed the limits of using the best off-the-shelf foundation models as black boxes, and it’s the correct time for roboticists to take on more of the full learning stack, and build a robotics-first foundation model.

But perhaps more importantly, I argue that robot foundation models are necessary for general deployment across society. We only have one existence proof of a technology that is general, robust, and flexible enough to even consider interfacing with the unconstrained open world: data-driven internet scale foundation models. If we wish for helpful generalist robots to really make an impact in the unstructured world, we’re going to need to take a big leap from where robotics research has been thus far; from single bins, single rooms, single labs, and single buildings all they way to the chaotic distributions of real-world scenarios.

I am often inspired by seeing what has worked well in foundation modeling (especially in language modeling), at both an algorithmic but also systems level. The field of AI is an engineering science, and I really appreciate how foundation modeling has matured to better understand the phenomena of what works in foundation modeling and why they work. Specifically, I am a big fan of the progress that’s been made on understanding the scaling laws and learning dynamics of large-scale training runs, of setting up models with diverse data with high-bandwidth contexts, and creating fairly predictive and scalable evaluations. It’s not obvious at all to me what the corollary of these in robotics is like.

And because of that, I’ll drop my first hot take: because the progress in building Robot Foundation Models is so far from the maturity that we see is required in foundation modeling to get some semblance of “it just works”, I claim that today’s state-of-the-art technology is not yet ready for general purpose robotics. If you froze today’s algorithms, model architectures, and data collection practices (and just scaled money, compute, data operations), it would not be enough to solve robotics. That’s not to say that freezing today’s technology/science stack is not sufficient for building great robotics commercial applications, positively impacting many lives, or disrupting specific industry verticals. But today’s bleeding edge is not yet there for solving general robotics, in any sense of the word. At least one or two paradigm shifts remain. I suspect that this hot take will be extremely obvious to many people, but also a bit heretical to many, especially in the Bay Area.

That brings us to the first fundamental open challenge: understanding the scaling laws of robotics.
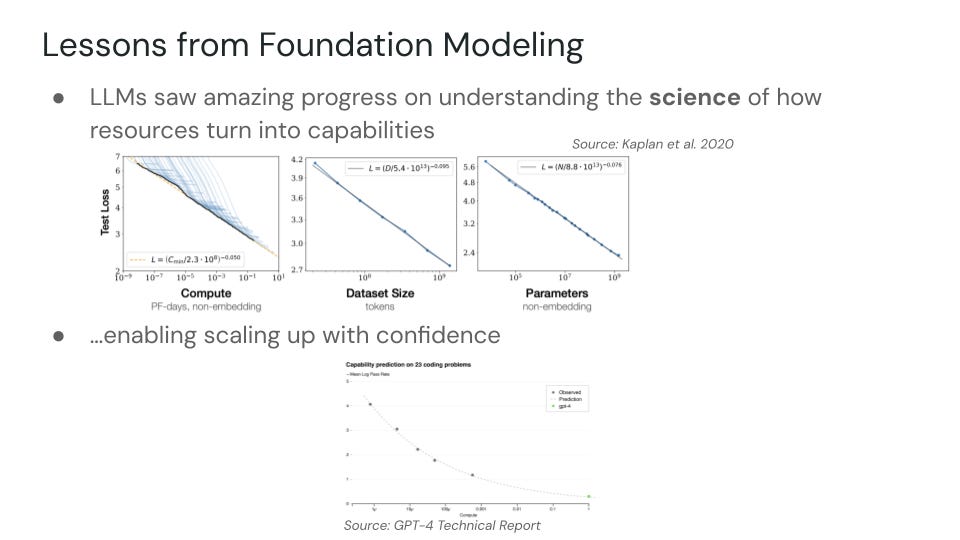
Language modeling was able to hyperscale rapidly as a field thanks largely to the early progress in understanding scaling properties. By gaining confidence in the rough power laws of language model scaling and the relationships between compute and dataset size, one could predictably connect the dots between input resources and output capabilities. But what about robotics?

In robotics, scaling up has often come with some substantial costs. For example, while scaling single-task RL to multi-task RL often gives sample efficiency gains, this often comes at a tradeoff of lower per-task asymptotic performance. But just like language modeling, I would argue that the power of scaling in robotics should only be measured under the most challenging steelman setting: if you only care about robot capabilities in a specific target scenario, when does scaling up help?

One data point on how scaling helps can be seen in the ablation study in RT-1. We found that increasing data quantity and data diversity were important for both in-distribution and OOD performance – but importantly, data diversity mattered more.

The second data point we’ve seen is that by training on robotics action data in conjunction with internet data, which is completely unrelated to robotics or physical interaction, transferred new semantic and visual knowledge to low-level robot control! In RT-2, a Vision-Language-Action (VLA) Model, we saw that robot policies began to exhibit signs of understanding symbols, reasoning, human recognition, and OCR, even though the robot action data never contained these types of data.

Finally, perhaps one of the more surprising results we’ve seen is that by adding data from different robots, you can actually improve performance on your target robot. In the Open X-Embodiment project we tested RT-X, a VLA trained on data from over one million open-source trajectories from many different robots, against specialist policies which were optimized for and trained only on data from the target evaluation scenarios. We were pleasantly surprised to see that the generalist checkpoint outcompeted numerous specialist policies, an especially challenging bar to beat since many of the specialist policies were methods designed explicitly for the particular embodiment and task setting.

But, while these data points of positive transfer give us some optimism that robot scaling may follow similar trends as language modeling, these positive signs are still far from guaranteed and are still fairly inconsistent; positive transfer is still more rare than it is common. To highlight some concrete examples of when positive transfer does not seem to work reliably, we find that VLAs still have fairly arcane training dynamics in terms of when generalization and positive transfer happens.
Even though VLA models might retain some VQA capabilities and generalize some semantic knowledge to actions, the reverse has not always been true; asking VQA-esque questions in robotics visual scenes sometimes does not result in valid text responses. Similarly, although VLA models sometimes exhibit emergent task planning and reasoning (such as asking for a Chain-of-Thought task plan before predicting the action), this is not always robust: even when the task plan is correct (“What object is useful for hammering a nail” => “Rock”), the subsequent action prediction may be wrong (“Rock” => {Action for picking up an apple})!
VLA training is still more of an art than a science, and many design decisions are not well understood. From action tokenization and formatting to dataset weights, there are many open questions about how to systematically train and scale VLAs.

On the data side, I’m excited to see recent works propose first attempts at quantifying scaling trends in robotics.

However, a lot of past efforts at measuring such scaling ablations have not unfortunately been domain-specific; scaling laws which work for one robot (ie. Kuka) on one set of tasks (ie. bin-picking) with one learning method (ie. online RL) do not apply to different robots (ie. Google robot) in different settings (ie. mobile manipulation) with different learning methods (ie. multitask imitation learning).
This leads me to one of my spicier hot takes in this talk: the axes of robot scaling laws will likely not be the same axes as language model scaling laws! Not all robot tokens are equal, and some robot tokens are extremely less information-rich than others; as a simple example, consider the utility of thousands of hours of autonomous robot data of waving a gripper around in free-space, compared to optimal expert demonstrations of a complex industrial assembly task, compared to extremely diverse but suboptimal play data. It’s highly likely that the quality, distribution, diversity, and coverage of robotics data will matter significantly more than data quantity alone. So until we gain a stronger understanding of what actually matters in scaling up robot foundation models, naively scaling data might be premature
If you consider many large-scale robotics datasets collected in the 2010s or earlier, many of those datasets – tens of thousands of hours worth! – did not pass the test of time and are not used at all today. I hope that the same does not happen with recent data scaling efforts. On the bright side, I think that these contributions will shed more light on pushing robotics research forward, which is already a worthy cause in itself.

The second missing piece for robot foundation models is expanding the context bandwidths of foundation models – a key to unlocking promptable robot policies. But what exactly does this mean?
When we think about what has unlocked general capabilities in language models, it’s largely been enabled by large-scale diverse datasets combined with long training contexts (and even longer inference contexts, up to millions of tokens). But robotics has operated very differently. Most robot policy interfaces, the way goals and instructions are communicated, have been extremely constrained, ranging from 1-hot task IDs to simple language templates. The bits of conditioning information given to robot policies has been a microscopic fraction of the rich input and output contexts utilized in language modeling.

And even if we decided to expand the language context bandwidth given to robots, it’s unclear if it’s enough. Language has been a convenient modality to utilize with robotics due to the robustness of LLMs and VLMs as powerful building blocks which happen to work very well with text – but there are so many robotics and physics concepts which are extremely hard to shoehorn into language. How would one even begin to use language to convey the richness of precise geometric robot trajectories, the subtleties of specific contact or friction forces, or the nuances of precise orientations or rotations required to perform dexterous domain-specific tasks?
Let’s look at a few examples of potential ways we can go beyond low-bandwidth simple language interfaces.
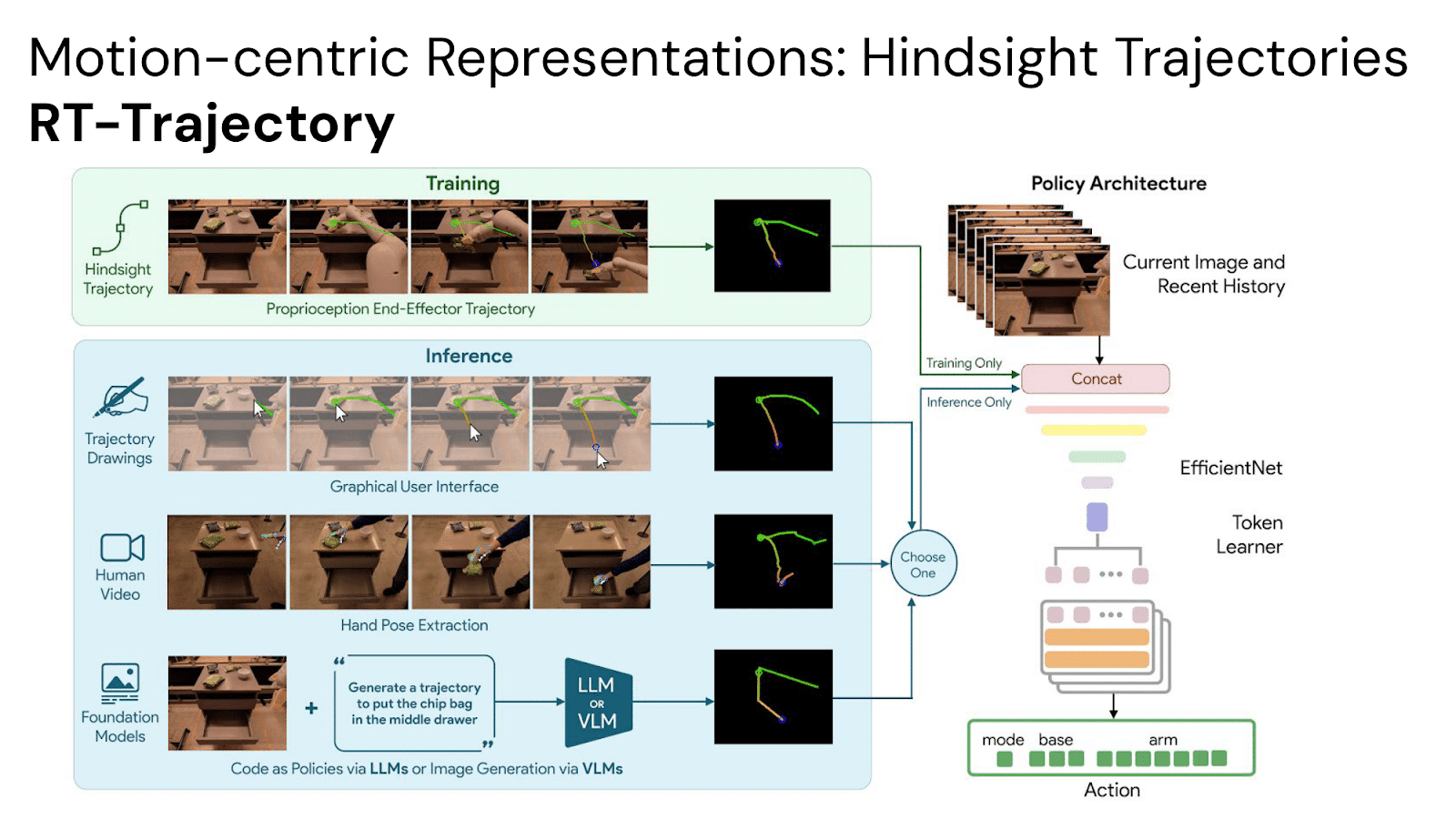
One way to go beyond language is to emphasize what’s unique and critical for robots: physical motions. Can we focus the policy conditioning on motion-centric representations which show the robot not just what to do, but also how to do it? In RT-Trajectory, this is accomplished with motion trajectories of the robot’s end-effector, presented as RGB images. During training, these trajectories can be provided for free via hindsight relabeling, and during inference time new motion trajectories can be flexibly provided by manual drawings, hand pose extraction from human videos, or even generated automatically via pretrained LLMs or VLMs.
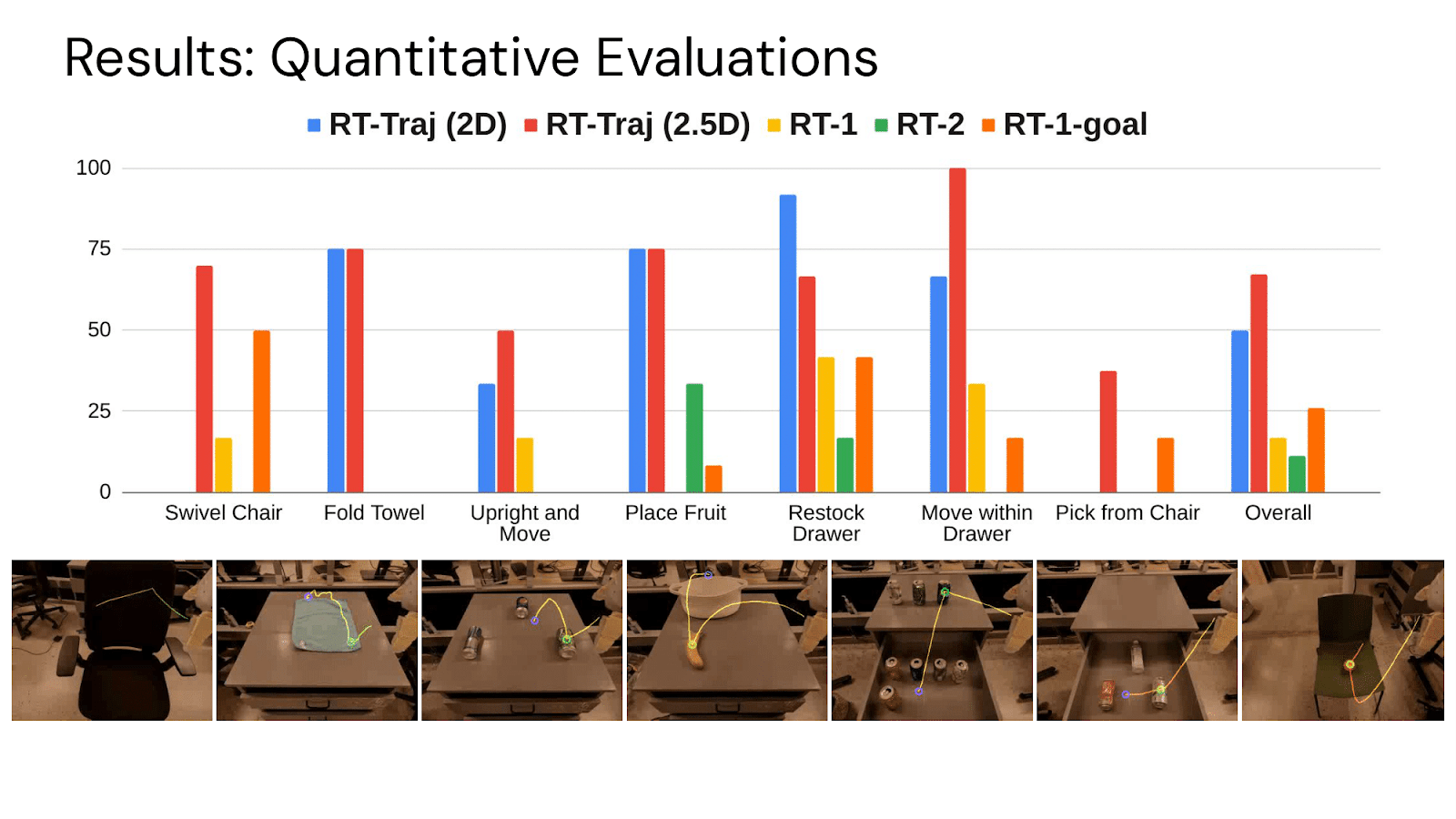
Using these coarse trajectory sketches as policy conditioning enables better generalization, including on tasks requiring new motions, such as swiveling a chair or picking objects from unseen heights.

But perhaps most exciting to me, was that this was one of the first times I’ve seen prompt engineering for a robot. We deployed our robot to a brand new environment, and manually drew trajectories for the robot to accomplish new tasks. Sometimes the robot would fail on the first attempt; for example, it was close to picking up the TV remote from a drawer it’s never seen before, but because it had never been trained on data from that drawer, its grasp attempt was a bit too high. Then, we could re-try the exact same task, starting from the same initial condition, but just provide a new trajectory that instructed the robot to reach lower – and the second try would work! This kind of prompt engineering was a pleasant surprise: that for a given initial condition, you could get better performance from a robot by just asking it better.

It’s been heartening to see a lot of other researchers interested in bringing motion-centric representations to robots. I’m particularly excited by works like RoboTap, ATM, Track2Act, and GENIMA!
Another way to approach high-bandwidth contexts for robot foundation models is to not only start from what’s important for robotics, but to also consider existing VLA training distributions. The internet contains a ton of semantically rich information, particularly from datasets covering VQA and spatial reasoning. Is there a way we can incorporate a robot policy interface that can act as a bridge from these diverse VLA training distributions?

In RT-Affordance, we study propose affordances as an intermediate interface that’s close to existing VLA training distributions, while still covering robotics-critical attributes; in particular, we propose a visual affordance representation that covers the rotation and position of the robot end-effector at key points in episodes.
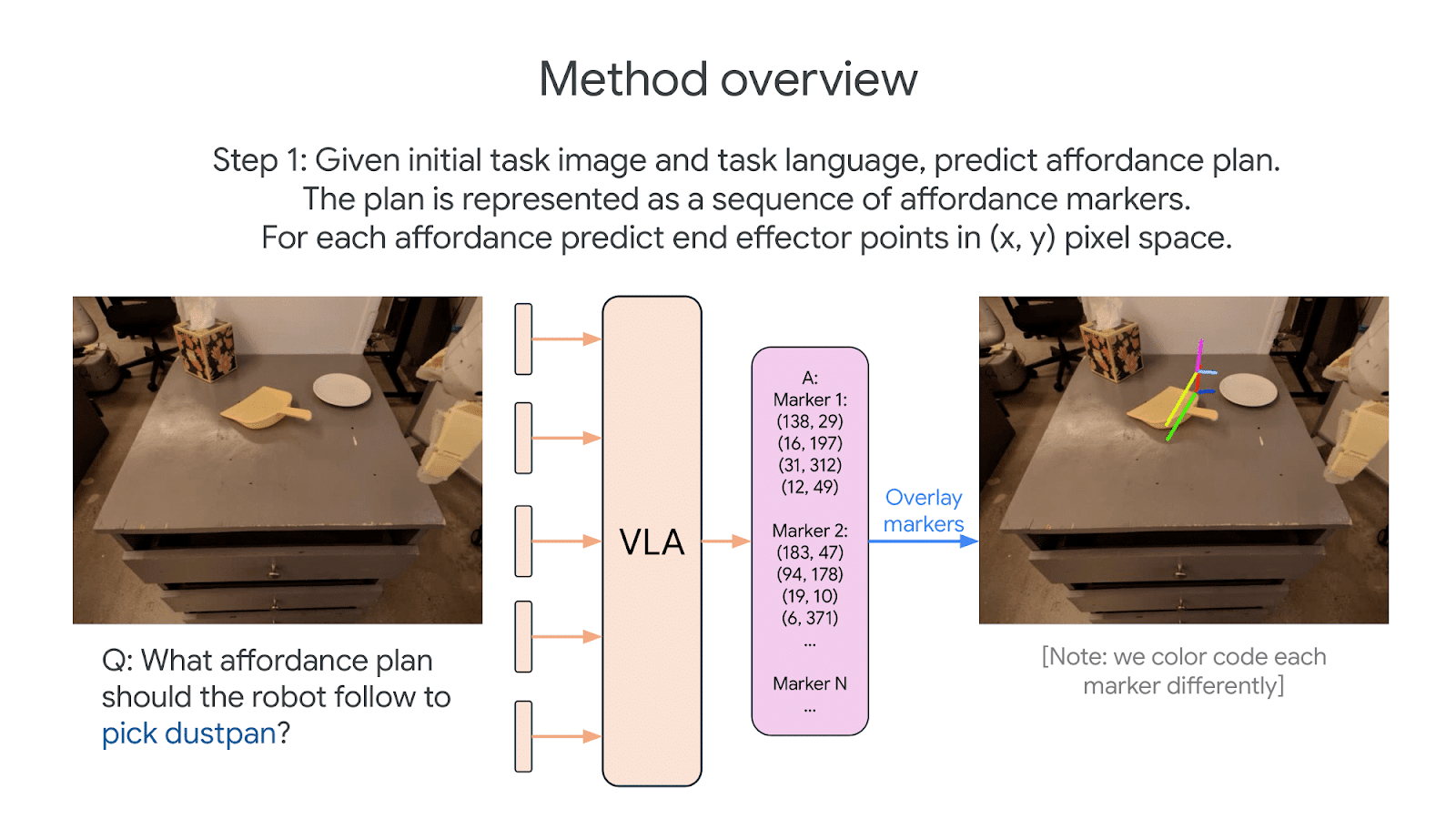
We adjust VLA training to first predict these affordances as text; then we project the affordance onto the camera image.

Afterwards, the VLA predicts the original low-level robot action, just as before. But now, it’s been able to use affordance predictions as a kind of visual Chain of Thought!
We find that these affordances enable better generalization in a variety of scenarios, particularly for challenging objects requiring specific manipulation strategies, such as kettles, pots, and dustpans. And when extracting affordance training data from existing demonstrations isn’t enough, we find that collecting non-action affordance data – literally just collecting the affordances for key manipulation steps, without the expensive intermediate robot actions – is enough to boost VLA performance in these OOD scenarios.

But taking a step back, I want to highlight that all of the works discussed so far, from RT-2 as the first VLA to RT-Trajectory to RT-Affordance, are all works which tackle end-to-end training of the foundation model (the “reasoning”) as well as the low-level control. In contrast, there are other ways to view the search space of how to build robot foundation models. Another camp is to view low-level control as completely abstracted away, to push as far on the foundation model side as possible; works such as SayCan, Embodied CoT, or Inner Monologue fall under this camp.
There is another perspective, however: if you assume that foundation models are going to get increasingly better, and that their improved reasoning capabilities can be more or less swapped out. Could we then focus on the low-level control, and design robot action policies with the knowledge that they will be utilized downstream by a very smart high-level orchestrator, such as a foundation model or a human? What would such a low-level policy optimized with a high-level planner in mind, look like?

Since foundation models interface with language, it seems like a good starting point to assume that the foundation model is going to orchestrate our low-level policy with text. But for all the reasons I started this section of the talk with, language is not perfect, at least the ways we have been using it so far! The language instructions we’ve used with our robots are either extremely templated and high-level, or extremely detailed down to the time horizon of seconds. It’s not clear whether either of these extremes is a great fit if we’re thinking about what an off-the-shelf foundation model can flexibly leverage. Is there a happy medium we can find?
In our recent project STEER, we propose dense language labeling of object-centric skills: providing detailed language descriptions at the happy medium between too high-level and too low-level by allowing the training data distribution to determine the set of language skills we use, as opposed to assigning explicit skills a priori.

To search for these object-centric skills, we search for distinct clusters of meaningful skills, and label them in language. By applying these skills to hindsight label existing demonstrations, we aim to ground robot episodes at the appropriate abstract level required to learn composable skills which cover all possible behavior modes, purely in language-conditioning alone!

Then, when we utilize high-level orchestration of low-level skills given a language instruction like “pick up the potted plant without disturbing the plant”, under the hood the low-level policy is receiving a sequence of object-centric skill language instructions, allowing STEER to accomplish this dexterous task, while training on the same original set of robot demonstrations as the other methods RT-1 and OpenVLA.

The improved language steerability of the low-level policies helps for both human orchestrators as well as VLM orchestrators. We find that Gemini 1.5 Pro is able to still perform successful zero-shot steering in numerous settings!

As a brief recap, we just explored a few potential opportunities for going beyond simple low-bandwidth language, and adding richer information conditioning signals for robot policies. We saw the benefits of motion-centric trajectory inputs which enabled prompt engineering, we saw how affordances could act as a bridging interface for VLA data distributions, and we finally saw how far we could go with explicitly optimizing a low-level policy for language steerability.
The progress in these proof-of-concept ideas give me hope that we’re on the right path towards creating flexible and promptable robots. But none of these ideas have thus far passed the test of scale, and that’s truly where a lot of open questions remain.

These open questions lead me to my next hot take: that large-scale data is necessary but just as important is to ensure we are collecting the right kinds of robot data. Our end goal is promptable robot foundation models; the path we take to get there and the algorithms we lean on will have very different data requirements. Will it be more important to collect passive human-activity data (ie. Ego4D), puppeteered expert robot demonstrations (ie. ALOHA), exoskeleton based data collection (ie. UMI), AR/VR based remote teleoperation data (ie. TeleVision), high-level language instruction corrections (ie. YAY), or diverse robot play data (ie. Interactive Language)? A ton of capital, time, and interest is being poured into “robot data scaling” today, but robot data is far from one size fits all. By better understanding what kinds of robot data are critical, we’ll set ourselves up for scalable success in the long-term.

The final missing piece is also the piece that may become the most severe in the coming years: evaluation.

The entire field of AI has had evaluation problems, but especially robotics. When we start to build more and more general-purpose robot foundation models, their evaluation surface also expands exponentially. In the RT-series, our evaluation requirements often consisted of thousands of trials - a paltry number in most pure science fields, but an unprecedented scale larger than most robotic training datasets. If a robot can truly “do anything”, how do you quantify and measure that?
For LLMs, they were trained on human-centric data distributions, evaluations targeting human distributions seem to be the most informative. But robots are grounded in the immutable physical laws of the real world. How can we scalably evaluate these?

One way to shrink the evaluation surface is to decompose robot policy behavior into specific axes of robustness and generalization. If we can measure the gap between test and training scenarios for each of these generalization axes individually, can we evaluate more effectively?
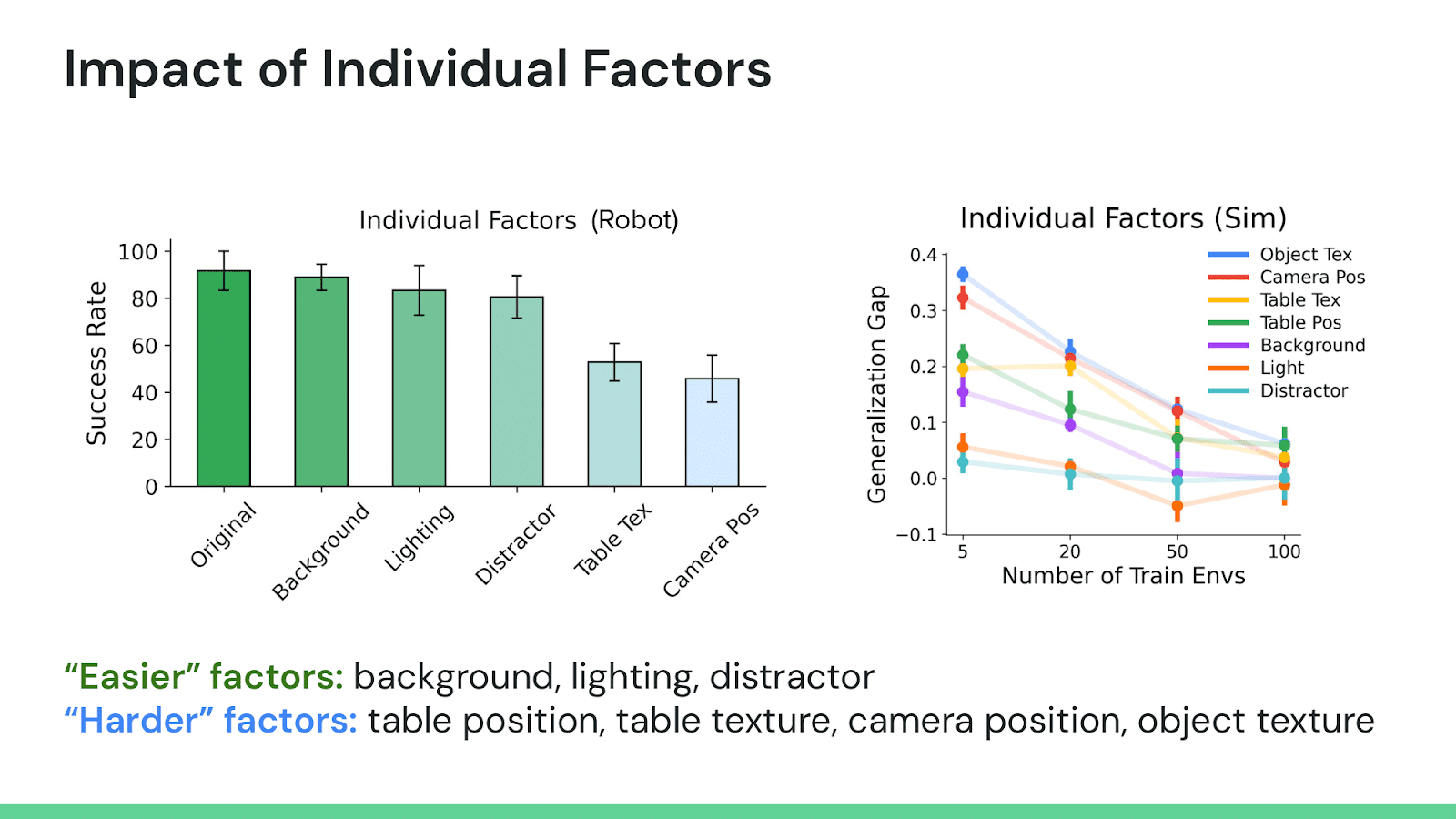
In our work GenGap, we attempted to do exactly this by studying the properties of robot policy generalization across different generalization axes, in both simulation and the real-world. We found some initial signals suggesting that these generalization gaps followed a rough hierarchy of easy to difficult – and more interestingly, the combination of multiple generalization distribution shifts were often equivalent to the harder of the two distribution shifts, rather than being compounding. These suggest that evaluating a subset of these individual generalization axes could be sufficient, even for understanding the generalization of a policy in aggregate!

But even with a reduced amount of evaluation trials, the time and resource cost of real-world world evaluations will quickly become intractable. Can we use simulation to alleviate this burden?
Sim2Real has been a popular regime (sim2real + RL has essentially solved locomotion) for policy learning, but robot manipulation foundation models have shifted to large-scale imitation learning from real data only. Even in such a setting, can simulation still add value, even if training in simulation is not universally accepted?
In SIMPLER, we studied whether or not policies trained only on real data could still be evaluated in simulation to give predictive success rates. The key insight is that as long as the ranking between different models is preserved between sim and real evaluations, the simulation eval is free lunch! We find that for many popular open-source models such as RT-1, RT-1-X, and Octo, we find a consistent ordering. Policies which perform better in simulation also perform better in the real world.

A related solution would be to use world models or action-conditioned video generation for evaluation – essentially relying not just on engineered physics engines, but on data-driven simulations. There’s substantial progress being made here, and the AV industry already relies heavily on simulated evaluations at scale.

Relying on world models is challenging, however. All good robot policies are good in roughly the same ways, but bad robot policies are often bad in each of their own unique ways; there are usually significantly fewer ways to do something right than to do it wrong. And for world models to successfully model the world to a fidelity where than be leveraged for robot policy evaluation, they may have to learn to model significantly more information than a robot foundation model to begin with; where a world model may need to learn to model what happens when a dish shatters and falls into a sink, a robot foundation model could get away with just learning to avoid that outcome entirely.
In the long-run, I do believe that there may be some unified world model and action prediction model; but in the short-run of the next few years, I claim that real-world evals will still be the gold standard.

And finally, let’s zoom back out and think about what comes next.

These three missing pieces will shape the next years of robot learning research: understanding Robot Scaling Laws, increasing Robot Context Bandwidths, and unlocking truly Scalable Evaluation systems. But let’s first grade how the field of robotics and AI is doing today, in 2024. I would first think about the initial signs of life and data points we’ve seen at the bleeding edge, and then think about what’s left to do.
For understanding Robot Scaling Laws, we’ve seen numerous points now that positive transfer from scaling can and does happen – much more often than before, but still not every time. It’s not always obvious a priori what the causal relationship is between input (data, compute, algorithm) and desired output (robot capabilities, generalization, mastery). But since we’ve seen this positive transfer happen a few times now (from multitask scaling, from internet data, from X-embodiment data), I would say that our progress is at a 6/10. For what’s coming next, I am looking forward to turning the art and alchemy of robot foundation model training into a science.
For creating promptable robots with High-Bandwidth Contexts, we’ve seen small-scale examples of ways to go beyond high-level language: with motion representations, with cheap non-robotics data sources like affordances, or with more steerable low-level control learning. But none of these methods have yet passed the test of scale, and the data to enable these ideas at a foundation model level may not exist yet; I would say our progress here is at a 4/10.
And finally, for scalable evaluations, I think we’re struggling the most here. While this is not an intractable issue today, it will soon become one. We’ve seen initial signals from leveraging simulation in AV and manipulation, as well as some ideas of how you can reduce the evaluation burden by decomposing robot capability – but these are still exploratory. Robot evaluation will become the biggest bottleneck of the 2020s. Due to the severity and limited progress we’ve seen so far, I will grade our progress as a 3/10.
To tackle these large gaps, I expect to see some significant changes in how robotics + AI evolves in the coming year and beyond. Robot foundation models today are making progress, but a common sentiment I hear is that they are still nowhere near good enough where a researcher or practitioner can download the latest robotics action models and get reasonable zero-shot performance on a setting they care about. In LLM/VLM research, most projects can safely assume that >80% of the “work” has been done already, and they can reliably start from a great pre-trained checkpoint. In robotics today, maybe <5% of the “work” is done; most times, if you want your robot to do something you care about, you have to start from scratch or finetune so much that you didn’t save that effort after all. In the coming years, I suspect that great generalist robot foundation models will give most practitioners a starting point such that >30% of the “work” is already done. In early versions of this talk, I referred to this as a potential split of robotics research into pre-training and post-training; since then, Physical Intelligence already started to make exciting progress towards understanding the relationship between robot pre-training and post-training.
To tackle higher-bandwidth robot contexts that will unlock truly promptable robots, we’ll see how robot data flywheels in industry and startups are able to figure out the right type of data to collect, in addition to the unit economics of how to scale up those types of data collection efforts. Pay close attention to trends in how the unit economics of useful robot action tokens becomes cheap or even profitable.
And finally, we are speeding rapidly to substantial bottlenecks in robot evaluation. Evaluation approaches today are domain-specific, brittle, and expensive. This is still barely acceptable today, but will soon become intractable. Fortunately, there are some signs that simulators and world modeling can provide some initial offline signals. A major question will be how these turn into real world evaluations at scale as robots gradually become deployed in-the-wild applications.

I’m optimistic that we’re closer than ever to the dream of general foundation models! But there are still significant missing pieces and open research challenges. Let’s tackle these together as a community. Feel free to drop me a line with any questions or ideas you have.